

اختبارات أداء نموذج لغوي كبير لـ Cognee المضيف الذاتي
اختبار Cognee مع نماذج LLM المحلية - نتائج حقيقية
Cognee هي إطار عمل بلغة Python لبناء مخططات المعرفة من الوثائق باستخدام LLMs. لكن هل يعمل مع النماذج المضيفة محليًا؟
اختبار Cognee مع نماذج LLM المحلية - نتائج حقيقية
Cognee هي إطار عمل بلغة Python لبناء مخططات المعرفة من الوثائق باستخدام LLMs. لكن هل يعمل مع النماذج المضيفة محليًا؟

كيف أصلحت مشاكل الشبكة في أوينتو
بعد تثبيت نواة جديدة تلقائيًا، فقدت شبكة إيثرنت في Ubuntu 24.04. وقع هذا الموقف المزعج معي للمرة الثانية، لذا سأوثق الحل هنا لمساعدته الآخرين الذين يواجهون نفس المشكلة.

منشور قصير، فقط أشير إلى السعر
مع هذه التقلبات المجنونة في أسعار الذاكرة العشوائية، لتشكيل صورة أفضل وفهمها بشكل أفضل، دعنا نتبع تتبع سعر الذاكرة العشوائية في أستراليا أولاً.

تزيد أسعار الذاكرة العشوائية (RAM) بنسبة 163 إلى 619% مع تزايد الطلب الناتج عن الذكاء الاصطناعي وتراجع المعروض
تواجه سوق الذاكرة تقلبات في الأسعار غير مسبوقة في أواخر عام 2025، مع ارتفاع أسعار الذاكرة العشوائية بشكل كبير في جميع الفئات.

أسعار وحدات معالجة الرسومات المخصصة للذكاء الاصطناعي - RTX 5080 و RTX 5090
لنقارن الأسعار بين أفضل بطاقات الجرافيكس من نوع GPU للمستهلكين، والتي مناسبة بشكل خاص للنماذج العصبية الكبيرة (LLMs) بشكل عام للذكاء الاصطناعي. بالتحديد أنا أبحث عن أسعار RTX-5080 و RTX-5090.

قم بتشغيل الذكاء الاصطناعي المؤسسي على معدات ميسرة بأسعار معقولة باستخدام نماذج مفتوحة المصدر
الديموقراطية في الذكاء الاصطناعي هنا. مع نماذج LLM المفتوحة المصدر مثل Llama 3، وMixtral، وQwen الآن تنافس النماذج الخاصة، يمكن للمجموعات بناء بنية تحتية قوية للذكاء الاصطناعي باستخدام معدات الاستهلاك - مما يقلل التكاليف مع الحفاظ على التحكم الكامل في خصوصية البيانات والنشر.

تفعيل تسريع وحدة معالجة الرسومات (GPU) لتشغيل نماذج Docker مع دعم NVIDIA CUDA
Docker Model Runner هو الأداة الرسمية لـ Docker لتشغيل النماذج الذكية الاصطناعية محليًا، ولكن تمكين تسريع GPU من NVidia في Docker Model Runner يتطلب تكوينًا خاصًا.

نتائج اختبار GPT-OSS 120b على ثلاث منصات ذكاء اصطناعي
قمت بتحليل بعض الاختبارات المثيرة للاهتمام حول أداء نموذج GPT-OSS 120b أثناء تشغيله على Ollama عبر ثلاث منصات مختلفة: NVIDIA DGX Spark، وMac Studio، وRTX 4080. يبلغ حجم نموذج GPT-OSS 120b من مكتبة Ollama 65 جيجابايت، مما يعني أنه لا يمكن أن يناسب الـ 16 جيجابايت من ذاكرة الفيديو (VRAM) الخاصة بـ RTX 4080 (أو النسخة الأحدث RTX 5080).
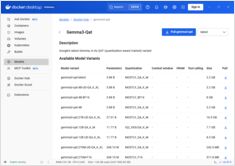
مراجع سريعة للأوامر الخاصة بتشغيل نموذج Docker
Docker Model Runner (DMR) هو الحل الرسمي من Docker لتشغيل نماذج الذكاء الاصطناعي محليًا، وقد تم تقديمه في أبريل 2025. يوفر هذا الدليل مرجع سريع لأهم الأوامر، والتكوينات، والممارسات المثلى.
إدارة بسيطة للآليات الافتراضية في Linux باستخدام GNOME Boxes
في بيئة الحوسبة الحديثة، أصبحت الافتراضية ضرورية لتطوير البرمجيات، والاختبار، وتشغيل أنظمة تشغيل متعددة. وللمستخدمين الذين يستخدمون Linux ويبحثون عن طريقة بسيطة وسلسة لإدارة أجهزة الافتراضية، يبرز GNOME Boxes كخيار خفيف وسهل الاستخدام يعطي الأولوية لسهولة الاستخدام دون التضحية بالوظائف.

تُسرّع الشرائح المتخصصة من إجراء استنتاجات الذكاء الاصطناعي، وتُقلّل تكاليفها
المستقبل الذكاء الاصطناعي ليس فقط عن نماذج أذكى النماذج - بل عن سيلكون أذكى.
العتاد المخصص لـ استنتاج النماذج الكبيرة يقود ثورة مشابهة لتغيير تعدين البيتكوين إلى ASICs.

التوافر، وسعر التجزئة في العالم الحقيقي عبر ستة دول، مقارنة مع Mac Studio.
NVIDIA DGX Spark هو حقيقي، متاح للبيع 15 أكتوبر 2025، ويستهدف مطوري CUDA الذين يحتاجون إلى عمل محلي على نماذج LLM مع مكدس NVIDIA AI المتكامل. السعر الموصى به في الولايات المتحدة 3999 دولارًا أمريكيًا؛ بينما يكون السعر في المملكة المتحدة/ألمانيا/اليابان أعلى بسبب ضريبة القيمة المضافة والقناة. لا تزال الأسعار الرسمية في أستراليا/كوريا غير متوفرة على نطاق واسع.

أسعار وحدات معالجة الرسومات الموجهة للمستهلك المناسبة للذكاء الاصطناعي - RTX 5080 و RTX 5090
مرة تلو الأخرى، دعنا نقارن الأسعار بين أفضل بطاقات الجرافيكس للمستهلكين من المستوى الأعلى، والتي مناسبة بشكل خاص للنماذج العصبية الكبيرة (LLMs) وبشكل عام للذكاء الاصطناعي (AI).
بالتحديد، أنا أنظر إلى
أسعار RTX-5080 و RTX-5090.
لقد تراجعت بشكل طفيف.
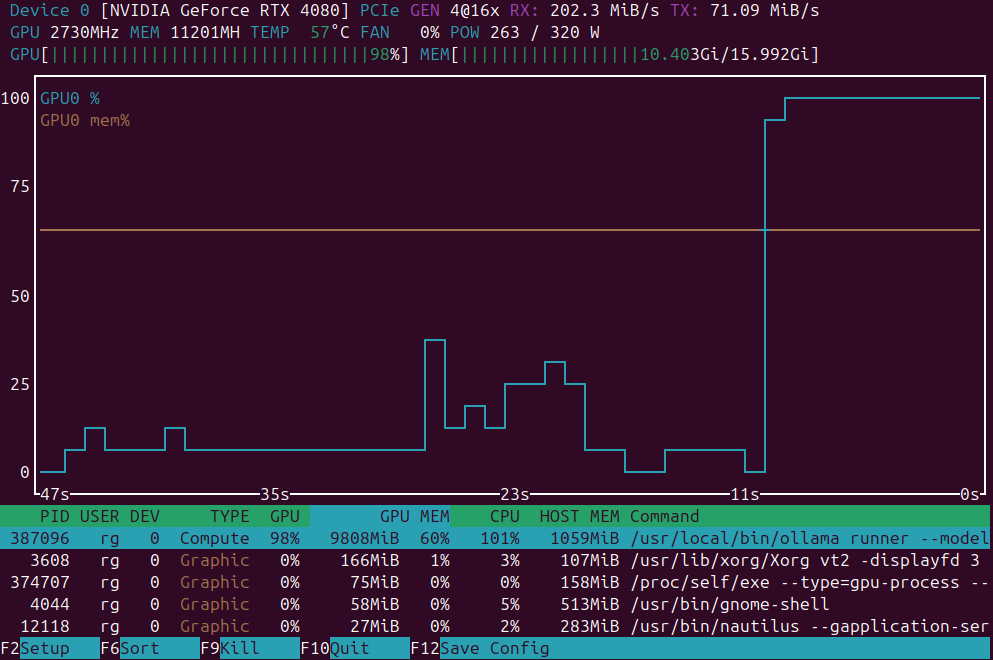
قائمة قصيرة توضح تطبيقات مراقبة حمل وحدة المعالجة الرسومية
[تطبيقات مراقبة حمل وحدة معالجة الرسومات (GPU)](https://www.glukhov.org/ar/post/2025/08/gpu-monitoring-apps-linux/ “تطبيقات مراقبة حمل وحدة معالجة الرسومات (GPU)): nvidia-smi مقابل nvtop مقابل nvitop مقابل KDE plasma systemmonitor.

في يوليو 2025، سيتم إتاحته قريبًا
نvidia على وشك إصدار NVIDIA DGX Spark - جهاز كمبيوتر صغير جداً لتشغيل الذكاء الاصطناعي بناءً على بنية Blackwell مع 128+ جيجابايت من الذاكرة الموحّدة و 1 PFLOPS من أداء الذكاء الاصطناعي. جهاز رائع لتشغيل نماذج الذكاء الاصطناعي الكبيرة (LLMs).

تحديث أسعار GPUs مناسبة للذكاء الاصطناعي - RTX 5080 و RTX 5090
لنقارن الأسعار بين أفضل بطاقات الرسومات الموجهة لمستخدمي الأجهزة النهائية، والتي مناسبة بشكل خاص للنماذج العصبية الكبيرة (LLMs) والأتمتة الذكية بشكل عام. ننظر بالتفصيل إلى أسعار RTX 5080 و RTX 5090. تراجعت الأسعار قليلاً.