

FLUX.1-Kontext-dev: نموذج الذكاء الاصطناعي لتعزيز الصور
نموذج الذكاء الاصطناعي لتعزيز الصور باستخدام تعليمات النص
لقد أطلقت مختبرات Black Forest FLUX.1-Kontext-dev، نموذج ذكاء اصطناعي متقدم لتحويل الصور من خلال استخدام تعليمات نصية.
نموذج الذكاء الاصطناعي لتعزيز الصور باستخدام تعليمات النص
لقد أطلقت مختبرات Black Forest FLUX.1-Kontext-dev، نموذج ذكاء اصطناعي متقدم لتحويل الصور من خلال استخدام تعليمات نصية.

تفعيل تسريع وحدة معالجة الرسومات (GPU) لتشغيل نماذج Docker مع دعم NVIDIA CUDA
Docker Model Runner هو الأداة الرسمية لـ Docker لتشغيل النماذج الذكية الاصطناعية محليًا، ولكن تمكين تسريع GPU من NVidia في Docker Model Runner يتطلب تكوينًا خاصًا.

احصل على خفض بنسبة 80% في تكاليف نماذج LLM من خلال تحسين ذكي للتوكنات
تحسين التوكنات هو المهارة الأساسية التي تميز التطبيقات الفعالة من حيث التكلفة بالتطبيقات التجريبية التي تستهلك الميزانية.
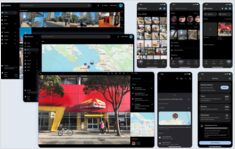
صورك في نسخ احتياطية مدعومة بذكاء اصطناعي مضيف ذاتي
Immich هو حل مبتكر ومفتوح المصدر لتنظيم وتخزين الصور والفيديوهات بشكل مستضاف ذاتيًا، مما يمنحك السيطرة الكاملة على ذكرياتك. مع ميزات تتنافس مع Google Photos، بما في ذلك التعرف على الوجوه الذكاء الاصطناعي، والبحث الذكي، والنسخ الاحتياطي التلقائي من الهاتف المحمول، مع الحفاظ على خصوصيتك وسلامة بياناتك على خادمك الخاص.

نتائج اختبار GPT-OSS 120b على ثلاث منصات ذكاء اصطناعي
قمت بتحليل بعض الاختبارات المثيرة للاهتمام حول أداء نموذج GPT-OSS 120b أثناء تشغيله على Ollama عبر ثلاث منصات مختلفة: NVIDIA DGX Spark، وMac Studio، وRTX 4080. يبلغ حجم نموذج GPT-OSS 120b من مكتبة Ollama 65 جيجابايت، مما يعني أنه لا يمكن أن يناسب الـ 16 جيجابايت من ذاكرة الفيديو (VRAM) الخاصة بـ RTX 4080 (أو النسخة الأحدث RTX 5080).

بناء خوادم MCP لمساعدي الذكاء الاصطناعي مع أمثلة بلغة بايثون
بروتوكول سياق النموذج (MCP) يُحدث طريقة تفاعل مساعدي الذكاء الاصطناعي مع مصادر البيانات الخارجية والأدوات. في هذا الدليل، سنستعرض كيفية بناء خوادم MCP في Python، مع أمثلة تركز على قدرات البحث عبر الإنترنت والتنقيب.
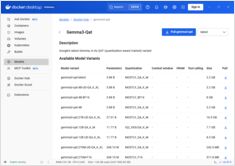
مراجع سريعة للأوامر الخاصة بتشغيل نموذج Docker
Docker Model Runner (DMR) هو الحل الرسمي من Docker لتشغيل نماذج الذكاء الاصطناعي محليًا، وقد تم تقديمه في أبريل 2025. يوفر هذا الدليل مرجع سريع لأهم الأوامر، والتكوينات، والممارسات المثلى.
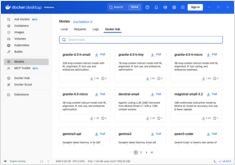
قارن بين Docker Model Runner و Ollama للذكاء الاصطناعي المحلي
تشغيل نماذج لغة كبيرة (LLMs) محليًا أصبح أكثر شيوعًا من أجل الخصوصية، والتحكم في التكاليف، والقدرات خارج الإنترنت. تغير المشهد بشكل كبير في أبريل 2025 عندما أدخلت Docker Docker Model Runner (DMR)، حلها الرسمي لنشر النماذج الذكية الاصطناعية.

تُسرّع الشرائح المتخصصة من إجراء استنتاجات الذكاء الاصطناعي، وتُقلّل تكاليفها
المستقبل الذكاء الاصطناعي ليس فقط عن نماذج أذكى النماذج - بل عن سيلكون أذكى.
العتاد المخصص لـ استنتاج النماذج الكبيرة يقود ثورة مشابهة لتغيير تعدين البيتكوين إلى ASICs.

التوافر، وسعر التجزئة في العالم الحقيقي عبر ستة دول، مقارنة مع Mac Studio.
NVIDIA DGX Spark هو حقيقي، متاح للبيع 15 أكتوبر 2025، ويستهدف مطوري CUDA الذين يحتاجون إلى عمل محلي على نماذج LLM مع مكدس NVIDIA AI المتكامل. السعر الموصى به في الولايات المتحدة 3999 دولارًا أمريكيًا؛ بينما يكون السعر في المملكة المتحدة/ألمانيا/اليابان أعلى بسبب ضريبة القيمة المضافة والقناة. لا تزال الأسعار الرسمية في أستراليا/كوريا غير متوفرة على نطاق واسع.

دمج Ollama مع Go: دليل SDK، أمثلة، وممارسات إنتاجية مثالية.
هذا الدليل يقدم لمحة شاملة عن مكتبات Go SDK المتاحة لـ Ollama ويقارن مجموعات ميزاتها.

مقارنة السرعة والparameters والأداء بين هذين النموذجين
هنا مقارنة بين Qwen3:30b و GPT-OSS:20b
متركزة على اتباع التعليمات والمؤشرات الأداء، المواصفات والسرعة:

ليس جيدًا جدًا.
نماذج GPT-OSS الخاصة بـ Ollama تعاني من مشاكل متكررة في التعامل مع الإخراج المهيكل، خاصة عند استخدامها مع الإطارات مثل LangChain، OpenAI SDK، vllm وغيرها.

بضع طرق للحصول على إخراج منظم من Ollama
النماذج الكبيرة للغة (LLMs) قوية، ولكن في الإنتاج نادراً ما نريد فقرات حرة. بدلاً من ذلك، نريد بيانات قابلة للتنبؤ: خصائص، حقائق، أو كائنات منظمة يمكنك إدخالها في تطبيق. هذا هو مخرجات LLM المنظمة.

اختباري الخاص لجدولة نموذج ollama ````
هنا أقارن كمية الـVRAM التي تخصصها الإصدار الجديد من Ollama للموديل مع الإصدار السابق من Ollama. الإصدار الجديد أسوأ.

رأيي في الحالة الحالية لتطوير أوالما
Ollama أصبح من بين الأدوات الأكثر شعبية بسرعة لتشغيل نماذج LLM محليًا. بواجهة سطر الأوامر البسيطة وإدارة النماذج المبسطة، أصبحت خيارًا مفضلاً للمطورين الذين يريدون العمل مع نماذج الذكاء الاصطناعي خارج السحابة. لكن كما هو الحال مع منصات واعدة كثيرة، هناك مؤشرات مبكرة على Enshittification: